Abstract
In this paper we address the problem of representing 3D visual data with parameterized volumetric shape primitives. Specifically, we present a (two-stage) approach built around convolutional neural networks (CNNs) capable of segmenting complex depth scenes into the simpler geometric structures that can be represented with superquadric models. In the first stage, our approach uses a Mask-RCNN model to identify superquadric-like structures in depth scenes and then fits superquadric models to the segmented structures using a specially designed CNN regressor. Using our approach we are able to describe complex structures with a small number of interpretable parameters. We evaluated the proposed approach on synthetic as well as real-world depth data and show that our solution does not only result in competitive performance in comparison to the state-of-the-art, but is able to decompose scenes into a number of superquadric models at a fraction of the time required by competing approaches. We make all data and models used in the paper available from https://lmi.fe.uni-lj.si/ en/research/resources/sq-seg.
Publication
Jaka Šircelj, Tim Oblak, Klemen Grm, Aleš Jaklič, Peter Peer, Vitomir Štruc, Franc Solina: Segmentation and Recovery of Superquadric Models using Convolutional Neural Networks, in Proceedings of the 25th Computer Vision Winter Workshop, Feb 2020, [PDF]
Overview
Dataset
A new dataset has been created specifically for multiple-superquadric scene reconstruction. The dataset consists of scenes containing from 1 to 5 superquadrics.


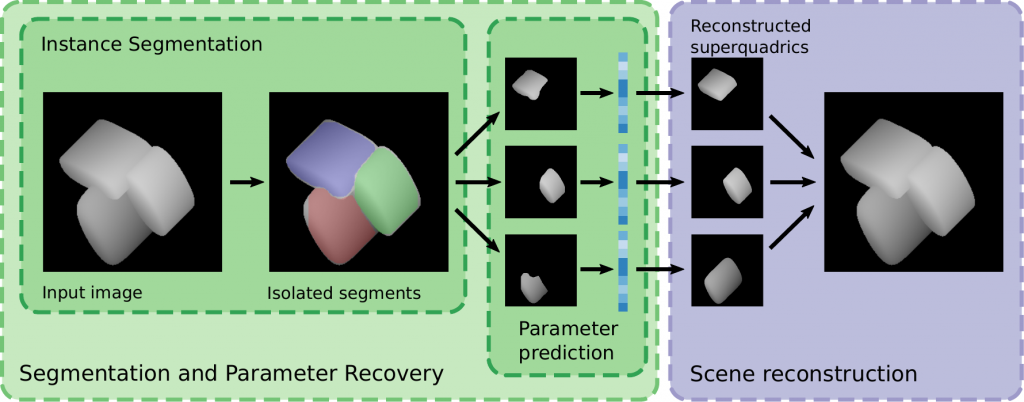
Segmentation and Parameter recovery
We introduce a novel method of multiple superquadric recovery. The method first segments the superquadrics using Mask R-CNN.
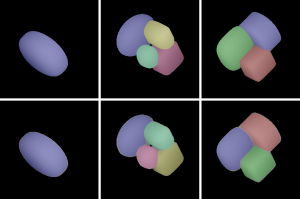


After the segmentation, we isolate each superquadric and pass it trough a VGG-like regressional neural network that predicts the shape, size and positional parameters. The following image shows the resulting reconstructed scenes using our model in semi-synthetic scenes constructed by joining range-images of individual real-world objects.
Synthetic scenes



Reconstructed scenes



Absolute Difference



More information can be found in our paper.
Download
The dataset is publicly available from the following links:
If you choose to use this dataset for your academic work please cite the following paper:
@inproceedings{Sircelj2020CVWW,
author = "{\v{S}}ircelj, Jaka
and Oblak, Tim
and Grm, Klemen
and Petkovi{\'{c}}, Uro{\v{s}}
and Jakli{\v{c}}, Ale{\v{s}}
and Peer, Peter
and {\v{S}}truc, Vitomir
and Solina, Franc",
title = {{Segmentation and Recovery of Superquadric Models using Convolutional Neural Network}},
year = {2020},
booktitle = {{Proc. Computer Vision Winter Workshop (CVWW)}}
}