Here you can find some useful resources created during our research work.
DISCLAIMER: Any code available from this side is provided “as is” without warranity of any kind. Since the software was written by different members of LMI, please have a look at the license under which specific software is made avilable.
Software
The Matlab INFace toolbox v2.1
{kind=link}

The INFace (Illumination Normalization techniques for robust Face recognition) toolbox is a collection of Matlab functions intended for researchers working in the field of face recognition. The toolbox was produced as a byproduct of the research work presented here. It includes implementations of several state-of-the-art photometric normalization techniques and a number of histogram manipulation functions, which can be useful for the task of illumination invariant face recognition.
Available from: INFace homepage, Matlab central
Documentation: PDF
The PhD face recognition toolbox

The PhD (Pretty helpful Development functions for) face recognition toolbox is a collection of Matlab functions and scripts intended to help researchers working in the field of face recognition. The toolbox was produced as a byproduct of the research work presented here and here. It includes implementations of several state-of-the-art face recognition techniques as well as a number of demo scripts, which can be extremely useful for beginners in the field of face recognition.
Available from: PhD toolbox homepage, Matlab central
Documentation: PDF
Face hallucination models

Here we make several state-of-the-art face hallucination models (or face super-resolution models) publicly available for the research community. All models have been trained on the CASIA WebFace dataset (>400k face images). The models have been implemented as part of our research on the paper “Face hallucination using cascaded super-resolution and identity priors” that appeared in the IEEE Transactions on Image Processing, 2020. The code includes our C-SRIP models as well as 10 state-of-the-art face hallucination models from recent top-tier vision conferences. See the C-SRIP homepage for a list of available models. Please cite the associated paper when using the models for you own research work. Commercial use is not allowed.
Available from: C-SRIP page
Description: PDF
Facial landmarking code

Facial landmark localization in 3D face data designed specifically to address appearance variability caused by significant pose variations. Our code uses a gating mechanism to incorporate multiple cascaded regression models each trained for a limited range of poses into a single powerful landmarking model capable of processing arbitrary posed input data. Two distinct approaches are developed around the proposed gating mechanism and made publicly available to the research community: i) the first uses a gated multiple ridge descent mechanism in conjunction with established (hand-crafted) HOG features for face alignment, ii) the second simultaneously learns multiple-descent directions as well as binary features that are optimal for the alignment tasks and in addition to competitive results also ensures extremely rapid processing. For more information on the landmarking approach see the project’s homepage. Please cite the associated paper when using the models for you own research work. Commercial use is not allowed.
Available from: BitBucket
Description: PDF
Datasets
Annotated Web Ears (AWE) toolbox and dataset

Annotated Web Ears (AWE) is a dataset of ear images gathered from the web and in the current form contains 1000 ear images of 100 distinct subjects. The dataset was collected for the goal of studying unconstrained ear recognition and is made publicly available to the community. The dataset comes with a Matlab toolbox dedicated to research in ear recognition. The AWE toolbox implements several state-of-the-art ear recognition techniques and allows for rapid experimentation with the AWE dataset.
Available from: AWE homepage
Description: PDF
Extended Annotated Web Ears (AWEx)
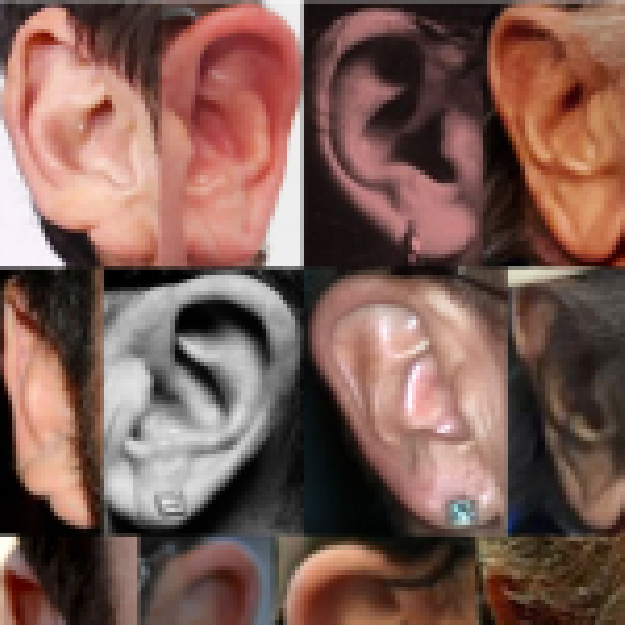
AWEx is an extended version of the AWE dataset and contains ear images of more than 330 subjects. The dataset is available upon request. For contact information follow the AWE homepage link below or send an e-mail directly to Žiga Emeršič.
Available from: AWE homepage
Description: PDF
Annotated Web Ears for segmentation AWE Dataset4Seg

This version of the AWE dataset contains 1.000 images of 100 persons with the pixel-wise annotations of ear locations. The dataset is available upon request. For contact information follow the AWE homepage link below or send an e-mail directly to Žiga Emeršič .
Available from: AWE homepage
Opis: PDF
The Sclera Blood Vessels, Periocular and Iris (SBVPI) dataset
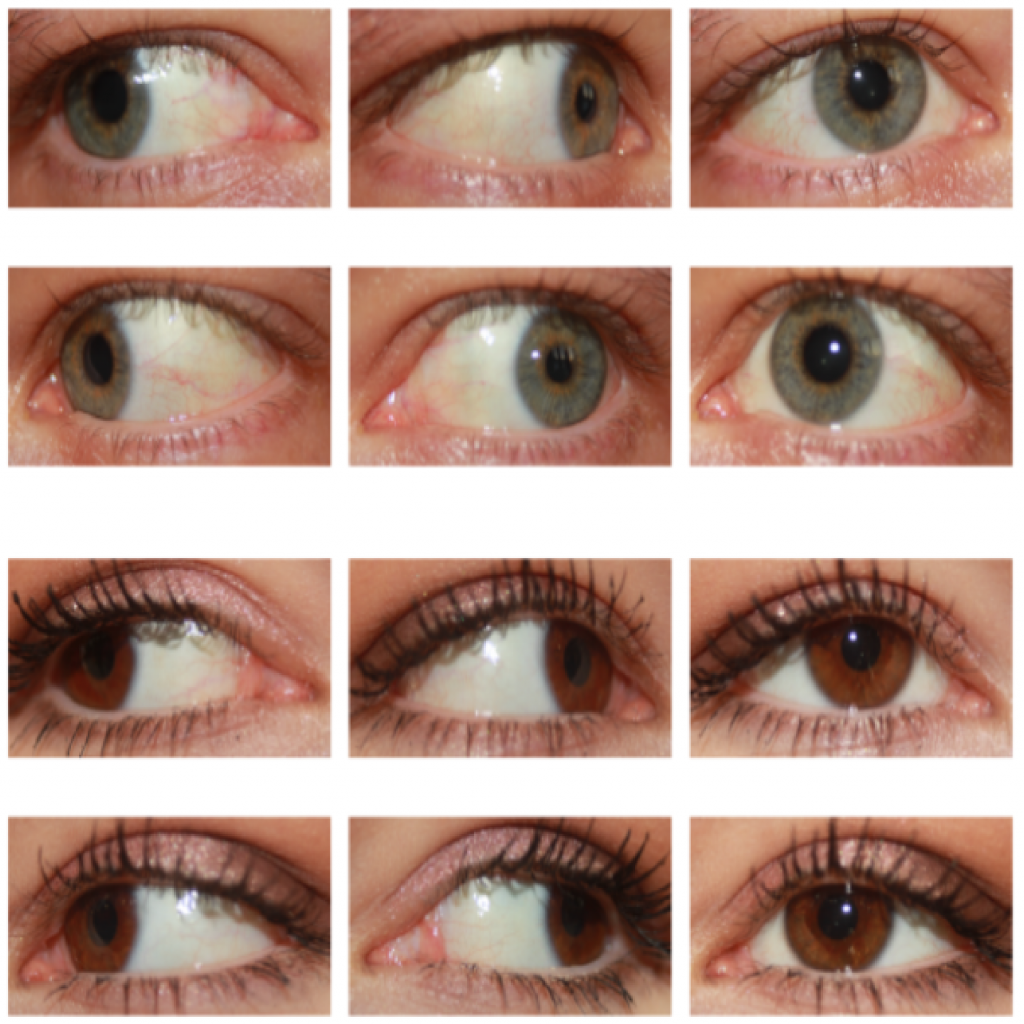
SBVPI (Sclera Blood Vessels, Periocular and Iris) is a publicly available dataset primarily intended for sclera and periocular recognition research. It was developed at the Faculty of Computer and Information Science, University of Ljubljana in 2018. It consists of 2399 high quality eye images (3000 x 1700 pixels) belonging to 55 different identities. For each identity at least 32 images with 4 different look directions (straight, left, right, up) are available. Each image is annotated with an ID, gender, eye (left/right), view direction and sample number labels. Unlike other similar datasets, it includes corresponding per-pixels annotations of sclera, sclera vascular structures, iris, pupil and periocular region.
Available from: SBVPI homepage
MOBIUS (Mobile Ocular Biometrics In Unconstrained Settings)
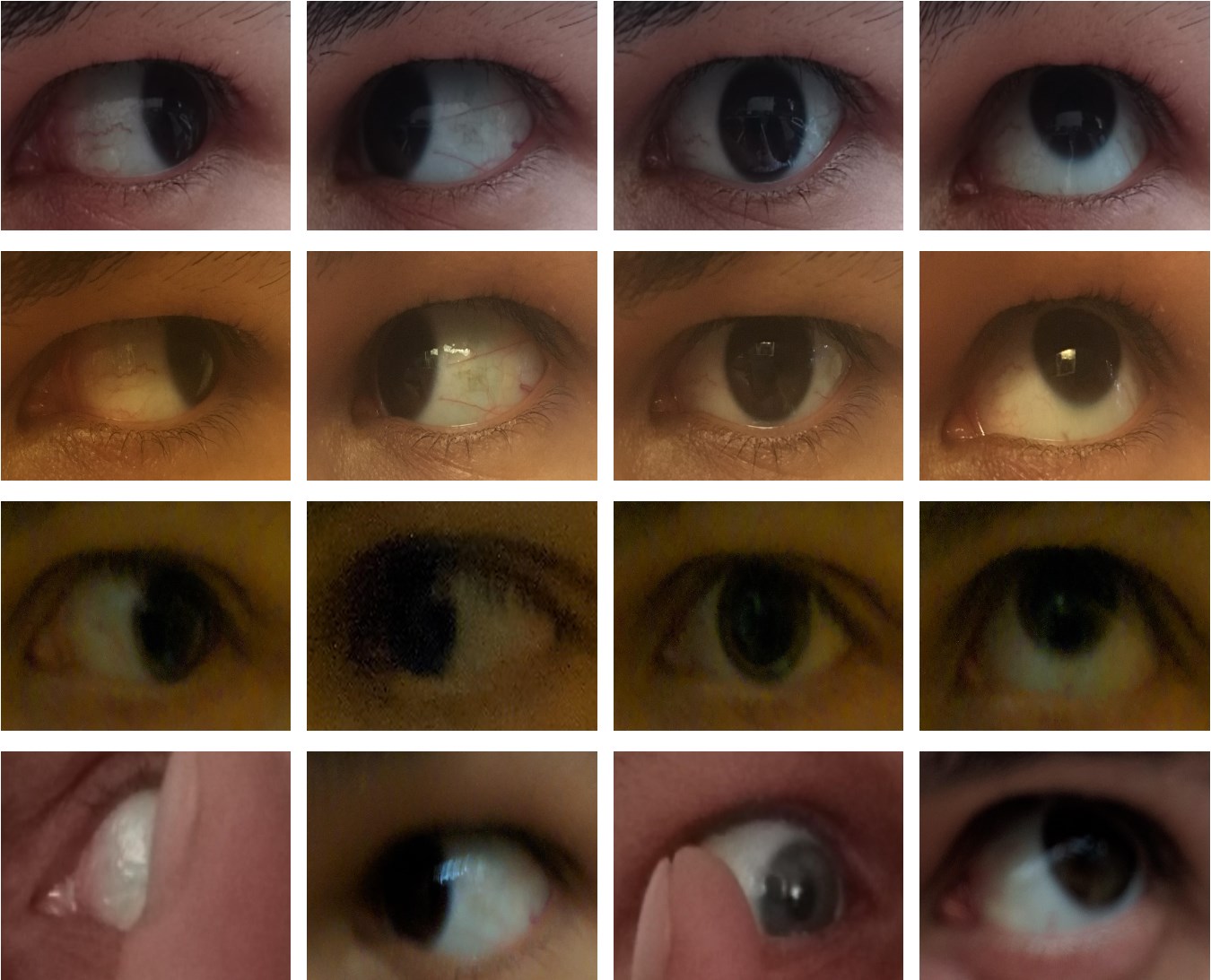
MOBIUS (Mobile Ocular Biometrics In Unconstrained Settings) is a publicly available dataset primarily intended for mobile ocular recognition research. It was developed at the University of Ljubljana in 2019. It consists of 16,717 RGB images collected from 100 subjects. The images are high-resolution and were captured with the cameras of 3 different commercial mobile phones — Sony Xperia Z5 Compact, Apple iPhone 6s, and Xiaomi Pocophone F1.
Available from: MOBIUS homepage
Segmentation and Recovery of Superquadric Models using Convolutional Neural Networks

In this paper we address the problem of representing 3D visual data with parameterized volumetric shape primitives. Specifically, we present a (two-stage) approach built around convolutional neural networks (CNNs) capable of segmenting complex depth scenes into the simpler geometric structures that can be represented with superquadric models. In the first stage, our approach uses a Mask-RCNN model to identify superquadric-like structures in depth scenes and then fits superquadric models to the segmented structures using a specially designed CNN regressor. Using our approach we are able to describe complex structures with a small number of interpretable parameters. We evaluated the proposed approach on synthetic as well as real-world depth data and show that our solution does not only result in competitive performance in comparison to the state-of-the-art, but is able to decompose scenes into a number of superquadric models at a fraction of the time required by competing approaches. We make all data and models used in the paper available from https://lmi.fe.uni-lj.si/research/resources/sq-seg/.
Available from: LMI website
Description: PDF
StreetVault: Dataset for Development of Privacy-Aware AIoT Vision Applications for Intelligent Urban Environments

StreetVault is a dataset tailored for the development and evaluation of privacy-aware AI vision systems in urban environments. Specifically, the dataset supports the training of object detection models on privacy-protected data acquired directly through a defocused optical system. The StreetVault dataset comprises paired high-quality and blurred street-level images captured in real-world conditions using a custom-built dual-camera embedded vision system.
Read more: HERE
MULTIAQUA: a multimodal maritime dataset for semantic segmentation

MULTIAQUA is a multimodal maritime dataset focused on providing data for multimodal semantic segmentation. It contains synchronized and spatially aligned data from several sensors, along with manual semantic annotations. The dataset was captured on inland and maritime waterways in Slovenia and contains various weather and visual conditions. A difficult nighttime test scenario is also included.