Abstract
In this work we address the problem of hallucinating high-resolution facial images from low-resolution inputs at high magnification factors. We approach this task with convolutional neural networks (CNNs) and propose a novel (deep)face hallucination model that incorporates identity priors into the learning procedure. The model consists of two main parts: i) a cascaded super-resolution network that upscales the low-resolution facial images, and ii) an ensemble of face recognition models that act as identity priors for the super-resolution network during training. Different from most competing super-resolution techniques that rely on a single model for upscaling (even with large magnification factors), our network uses a cascade of multiple SR models that progressively upscale the low-resolution images using steps of 2×. This characteristic allows us to apply supervision signals (target appearances) at different resolutions and incorporate identity constraints at multiple-scales. The proposed C-SRIP model (Cascaded Super Resolution with Identity Priors) is able to upscale (tiny) low-resolution images captured in unconstrained conditions and produce visually convincing results for diverse low-resolution inputs. We rigorously evaluate the proposed model on the Labeled Faces in the Wild (LFW), Helen and CelebA datasets and report superior performance compared to the existing state-of-the-art.
Publication
K. Grm, W. J. Sheirer, V. Štruc, Face hallucination using cascaded super-resolution and identity priors, IEEE Transactions on Image Processing, accepted 2020 [PDF, Appendix].
Overview
An overview of our model is presented in Figure 1.
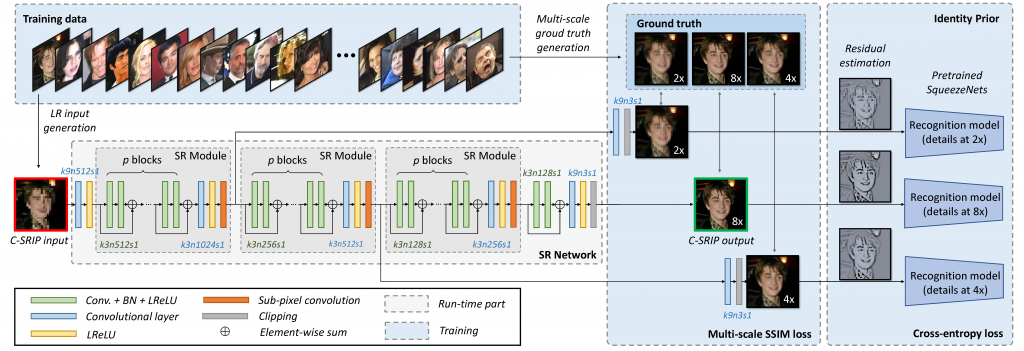
The model produces state-of-the-art face hallucination results as shown in the visual examples in the image below.

For more results have a look at the complete paper. A open-access preprint version of the paper is available from here.
Download
We make the face hallucination models developed during our research publicly available to the research community. All models were trained on the CASIA WebFace dataset (>400k face images). The models were built during our work on the article “Face hallucination using cascaded super-resolution and identity priors” that appeared in the IEEE Transactions on Image Processing, 2020 [PDF, Appendix]. The code includes our C-SRIP models as well as other state-of-the-art face hallucination models we used for the validation of our approach. Commercial use is not allowed. Please cite the following article when using the models for your own research work:
@article{grm2020face,
author={K. {Grm} and W. J. {Scheirer} and V. {Štruc}},
journal={IEEE Transactions on Image Processing},
title={Face Hallucination Using Cascaded Super-Resolution and Identity Priors},
year={2020},
volume={29},
number={},
pages={2150-2165},
doi={10.1109/TIP.2019.2945835},
ISSN={1941-0042},
month={},
}The following software was developed using python 3.5, tensorflow 1.14, keras 2.2.4, pytorch 1.0.0 and openCV 4.1.0, and may not work correctly with different library versions.
- C-SRIP – described in: Face hallucination using cascaded super-resolution and identity priors, K. Grm, W. J. Scheirer, V. Štruc, IEEE TIP 2020.
- LapSRN – described in: Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution, W. S. Lao, J. B. Huang, N. Ahuja, M. H. Yang, CVPR 2017
- CARN – described in: Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network, N. Ahn, B. Kang, K. A. Sohn, ECCV 2018
- l_p – described in: Perceptual losses for real-time style transfer and super-resolution, J. Johnson, A. Alahi, L. Fei-Fei, ECCV 2016
- URDGN – described in: Ultra-resolving face images by discriminative generative networks, X. Yu, F. Porikli, ECCV 2016)
- SICNN – described in: Super-Identity Convolutional Neural Network for Face Hallucination, K. Zhang, Z. Zhang, C. W. Cheng, W. H. Hsu, Y. Qiao, W. Liu, T. Zhang, ECCV 2018
- EDSR – described in: Enhanced deep residual networks for single image super-resolution, B. Lim, S. Son, H. Kim, S. Nah, K. M. Lee, CVPR-W, 2017
- VDSR – described in: Accurate image super-resolution using very deep convolutional networks, J. Kim, L. J. Kwon, K. L. Mu, CVPR 2016
- SRGAN – described in: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunnihgham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, W.shi, CVPR 2017
- SRCNN – described in: Learning a deep convolutional network for image super-resolution, C. Dong, C. C. Loy, K. He, X. Tang, ECCV 2014
We also include an example preprocessing script to demonstrate how we generated the training and test sets here.